I’ve been itching to write this article since I authored Python vs Copy on Write last year. To recap, I found myself awake at 4 AM trying to performance tune the cache on a long running ETL written in Python.
In a flash of pizza fueled, sleep deprived clarity, I remembered Brandon Rhodes’ talk on Python, Linkers, and Virtual Memory; because of reference counting, Python cannot take advantage of the Copy on Write optimization provided by the OS. An hour later I had a patch ready for our staging environment.
If you read my previous article, you may have been under the impression that my fix was a silver bullet and you’d be partially right.

The patch did have the intended effect of reducing the runtime of the areas of code that used the cache, but to my horror I found that I had created another bottleneck. We use psycopg2 to query our database, and our code was now spending hours running this line to create the new cache:
cursor.fetchall()
Thinking back to my long night of coding, I remember noticing that for some reason the range(very large number) function that I was using to generate the dummy cache in my experiments was taking a long time to run. So, I hypothesized that allocating a large list to store the fetchall results was bottle necking my process.
I refactored, reran the ETL in our staging environment and waited as fast as I could. Like magic, the ETL finished with more than a 40% reduction in runtime and I could console myself in that my sleep schedule would return to normal.
But, there was always the lingering question as to why large list allocations take so much time. So grab your gear, prime your Python, C and Unix cheat sheets and get ready for a deep dive into the python interpreter.

Tools
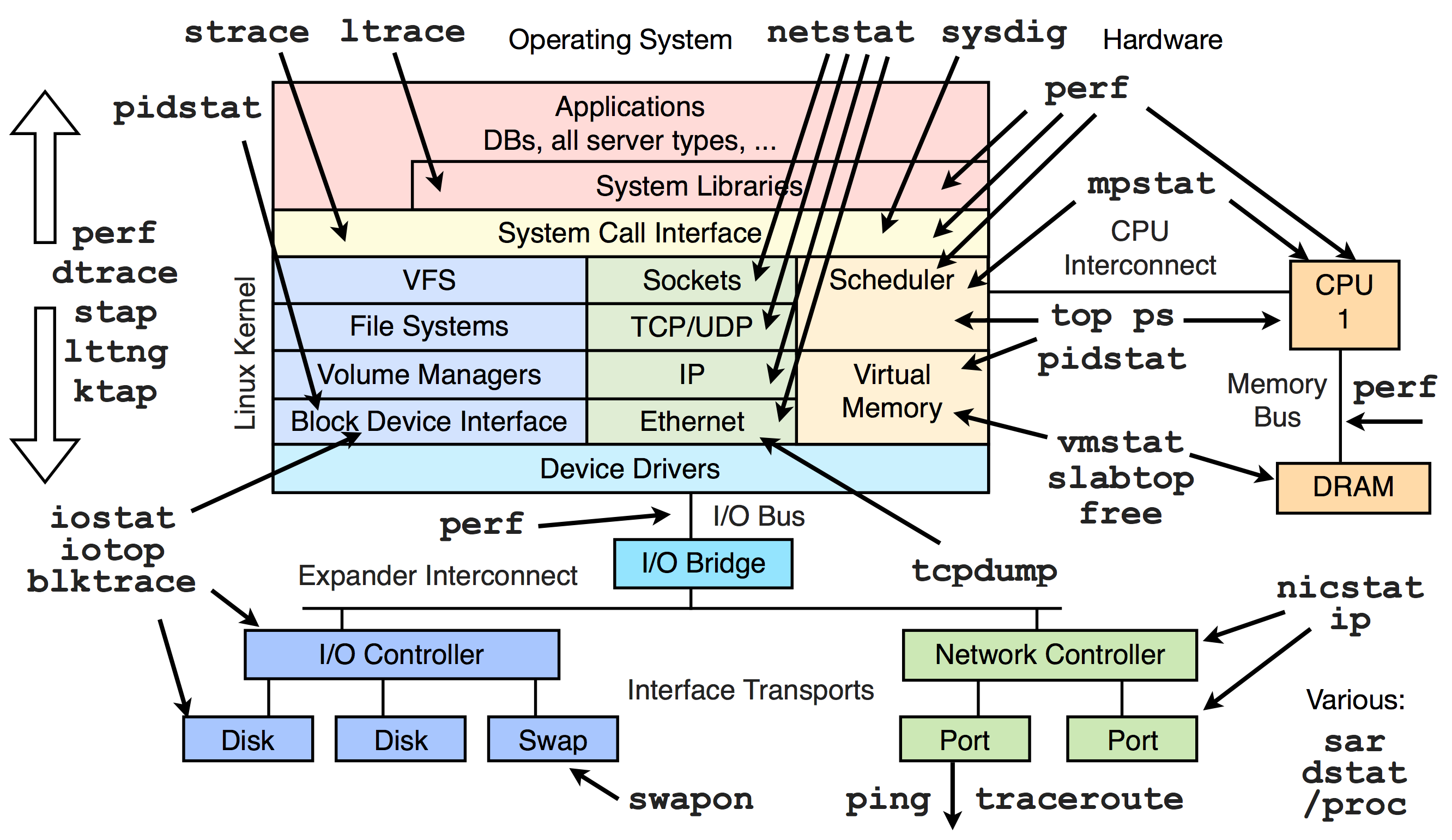
To avoid reading through the C Python interpreter’s source, we’ll run a number of Unix profiling tools on Ubuntu 16.04 against some simple examples. We will start with ltrace for standard library traces and strace for system call traces.
Then we will move onto Valgrind to thoroughly diagnose the problem. Valgrind is a framework that contains a number of dynamic analysis tools. Its Memcheck tool is commonly used to detect memory leaks. For our problem we will be using Massif, DHAT and Callgrind from the Valgrind suite.
We will start with Massif for heap profiling. Massif provides a timeline of allocated memory. We will then use DHAT for some summarized allocation statistics.
The bulk of our work will focus on Callgrind to profile the call history using a call graph. KCachegrind will let us visualize the call graph and determine exactly where our cycles are being spent.
I should note that part of my purpose in writing this blog is to demonstrate the use of these tools. Were I to perform a task like this for practical purposes, I would probably reach for Memcheck and Callgrind, and likely skip the rest.
Feel free to follow along by checking out this git repository. In most cases, I’ve encapsulated examples into single bash scripts. In this article, I’ll make a note of the path of the example I’m using and cat the bash script so that you can see its contents. I’ve also produced a docker image that will provide a version of Python 2.7 compiled to be run with Valgrind. In order to install docker, run the following:
$ sudo apt-get install docker.io
$ sudo adduser $USER docker
You may have to log out and log back in, in order to be recognized as a member of the docker group.

The Benchmark
To start, let’s go back to the program that started this whole investigation:
src/python/benchmark.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
range(10000000)
Remember the original hypothesis; allocating large lists of integers caused an increase in runtime. The range function in this case is a very easy way to create a large list of integers. The size parameter passed to range is somewhat arbitrary. It has to be sufficiently large to be noticeable on the machine you’re running on. In my case, the magic number is 10,000,000.
A brief note on the differences between Python 2.7 and Python 3; range is implemented differently. We can measure the difference using the Unix time command:
src/python/$ time python2.7 benchmark.py
real 0m0.404s
user 0m0.220s
sys 0m0.180s
‘real’ is the time from start to finish. ‘user’ is the time spent in user-mode code, outside of the kernel. ‘sys’ is the time spent in the kernel via system calls. Compare this runtime to the results from Python 3:
src/python/$ time python3.5 benchmark.py
real 0m0.040s
user 0m0.032s
sys 0m0.004s
Instead of allocating a populated list, Python 3 creates a Range object. I haven’t verified, but I assume the range object operates like a generator. To eliminate this complexity, we’ll stick with Python 2.7.
The C Python interpreter is a complex piece of software. In order to establish a baseline for understanding its operation, we’ll create a naively comparable program in C:
src/c/benchmark.c
#include <stdlib.h>
#define LENGTH 10000000
int main() {
// Allocate the memory.
int * buffer = malloc(LENGTH * sizeof(int));
// Seed the memory.
for (int index = 0; index < LENGTH; index++) {
buffer[index] = index;
}
// Free the memory.
free (buffer);
return 0;
}
Note that you will need to install some software to get this program to compile:
$ sudo apt-get install build-essential
A quick check with the time command:
src/c/$ make
rm -f benchmark
rm -f *.out.*
gcc -g -o benchmark benchmark.c
src/c/$ time ./benchmark
real 0m0.072s
user 0m0.064s
sys 0m0.004s
I understand that this is an apples to oranges comparison, but the differences we find should be illuminating. The simplified C program will also let us explore our tool set with something that is easy to understand. Right, it’s time to learn how to defend your runtime against a blogger armed with apple and an orange.

ltrace
ltrace is a program that lets us take a peek at the standard library calls being made by a program. As our C and Python programs are somewhat simple, ltrace should give us a quick idea of how different these programs are. First, the C program:
src/c/ltrace
src/c/$ cat ltrace
#!/bin/sh
ltrace ./benchmark
src/c/$ ./ltrace
__libc_start_main(0x400566, 1, 0x7ffdc5a20818, 0x400590 <unfinished ...>
malloc(40000000) = 0x7fa98820b010
free(0x7fa98820b010) = <void>
+++ exited (status 0) +++
As expected, the C program allocated all of the 40 MB of memory with a single command (malloc).
Second, the Python program. Running ltrace directly on the python script is somewhat unwieldy. We’ll have to filter the results. Lets start with a summary of the calls:
src/python/ltrace
% time seconds usecs/call calls function
------ ----------- ----------- --------- --------------------
47.46 10.684727 43 246094 free
44.10 9.927329 40 245504 malloc
2.60 0.585793 39 14734 memcpy
1.55 0.348615 40 8530 memset
1.26 0.283193 40 6962 strlen
1.03 0.231403 39 5819 memcmp
0.52 0.116267 43 2688 strcmp
0.41 0.091900 40 2248 __ctype_b_loc
0.18 0.041460 39 1040 realloc
0.18 0.040438 13479 3 qsort
0.11 0.023975 39 602 strchr
...
It seems that our script is spending the majority of its time on memory operations. Digging deeper into the mallocs, this script sorts and counts the calls based on the buffer size.
src/python/malloc
src/python/$ cat malloc
#!/bin/sh
ltrace -e malloc -l python python benchmark.py 2>&1 | sed "s/).*//" | sed "s/.*(//" | sort -nr | uniq -c
$ ./malloc
1 80000000
1 36654
4 36032
1 25593
1 25474
1 20808
1 19945
1 19712
...
1 1141
1 1105
1 1053
1 1034
243929 992
1 991
1 990
1 978
1 977
...
Two interesting observations can be made. The first is that there is a very large allocation being made; double the size of the C allocation. As we are interested in runtime, we also find that python is performing 243929 allocations of 992 byte buffers, or 242 MB.
As an aside, if you’d like to play around with ltrace and python, you can set the range in the benchmark program to something a bit more manageable, like 100. The output is still fairly unwieldy:
src/python/$ ltrace python -c "range(100)"
__libc_start_main(0x49dab0, 2, 0x7ffed23f7ab8, 0x5d71b0 <unfinished ...>
getenv("PYTHONHASHSEED") = nil
getenv("PYTHONINSPECT") = nil
getenv("PYTHONUNBUFFERED") = nil
getenv("PYTHONNOUSERSITE") = nil
getenv("PYTHONWARNINGS") = nil
fileno(0x7f26b16ec8e0) = 0
...
Among other things, we can see some of the built in functions being copied around in memory:
...
strlen("print") = 5
memcpy(0x7f1bf84e56b4, "print\0", 6) = 0x7f1bf84e56b4
strlen("range") = 5
memcpy(0x7f1bf84e56e4, "range\0", 6) = 0x7f1bf84e56e4
strlen("raw_input") = 9
memcpy(0x7f1bf84e5714, "raw_input\0", 10) = 0x7f1bf84e5714
...
We can also combine ltrace with tools like gnuplot to visually see the malloc calls over time. Note the size of the range parameter has been reduced so that we can see other allocations performed by the interpreter:
src/python/timeline
src/python/$ cat timeline
#!/bin/sh
ltrace -tt -e malloc -l python python -c "range(10000)" 2>&1 | grep "malloc" | sed "s/python.*(//" | sed "s/).*//" | gnuplot -p -e "set xdata time; set timefmt '%H:%M:%S'; plot '<cat' using 1:2 with lines"
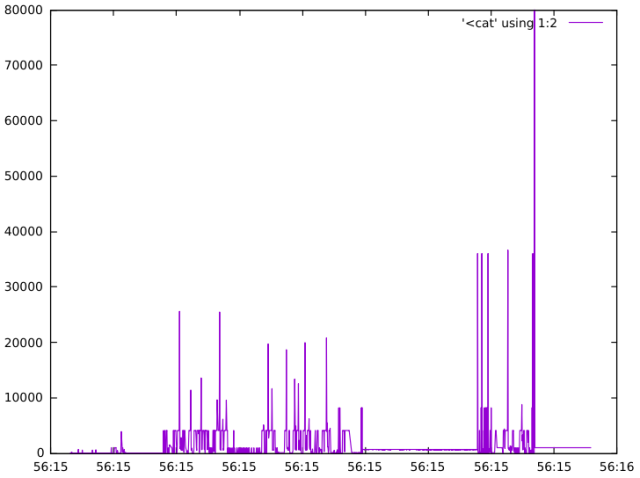
strace
Since we’re talking about ltrace, we may as well cover strace. strace lets us take a look at the system calls our programs are making. System calls are like functions that request the services from the kernel. They typically deal with resource allocation requests.
You can find a categorized list of them at System Calls for Developers. System calls are typically not made directly in code. Instead, wrapper functions in the form of a standard library are used. strace intecrepts these calls and prints them for inspection.
As before, we will start with our C program. We will filter everything except memory related calls:
src/c/strace
src/c/$ cat strace
#!/bin/sh
strace -e memory ./benchmark
src/c/$ ./strace
brk(NULL) = 0xaf0000
mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f5e8b790000
mmap(NULL, 125519, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7f5e8b771000
mmap(NULL, 3967392, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0x7f5e8b1a4000
mprotect(0x7f5e8b363000, 2097152, PROT_NONE) = 0
mmap(0x7f5e8b563000, 24576, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x1bf000) = 0x7f5e8b563000
mmap(0x7f5e8b569000, 14752, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0x7f5e8b569000
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f5e8b770000
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f5e8b76f000
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f5e8b76e000
mprotect(0x7f5e8b563000, 16384, PROT_READ) = 0
mprotect(0x600000, 4096, PROT_READ) = 0
mprotect(0x7f5e8b792000, 4096, PROT_READ) = 0
munmap(0x7f5e8b771000, 125519) = 0
mmap(NULL, 40001536, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f5e88b7e000
munmap(0x7f5e88b7e000, 40001536) = 0
+++ exited with 0 +++
The two calls of interest are the last two prior to exit (mmap and munmap), which correspond to the malloc and free calls respectively. We can infer this correspondence because mmap and munmap are called with a size of 40,001,536.
On to the python program. We’ll summarize the results again with the -c flag to reduce the size of the output:
src/python/strace
src/python/$ cat strace
#!/bin/sh
strace -c -e memory python benchmark.py
src/python/$ ./strace
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
100.00 0.000264 0 61837 brk
0.00 0.000000 0 29 mmap
0.00 0.000000 0 14 mprotect
0.00 0.000000 0 2 munmap
------ ----------- ----------- --------- --------- ----------------
100.00 0.000264 61882 total
It seems the bulk of our memory related system calls are brk calls and not mmap calls. What’s the difference between brk and mmap? brk is typically used for small allocations. mmap on the other hand lets you allocate independent regions without being limited to a single chunk of memory. It useful for avoiding issues like memory fragmentation when allocating large memory blocks.
As we found with ltrace, it seems that in addition to the large block of memory allocated by mmap, the python process also allocates a large number of small memory blocks with brk.
The Environment
So far, ltrace and strace have been useful for getting an overall understanding of the differences between the C and Python programs. However, the results we’ve gotten have been either too detailed or too summarized to draw useful conclusions. We need to try something completely different.

To dig deeper into this problem, we’ll need better tooling. That’s where Valgrind comes in. Valgrind is a framework that contains a number of dynamic analysis tools. There’s a catch; we will need to compile our programs for debugging.
For the C program, this process is easy; it’s already compiled this way via its Makefile. All you need to start running Valgrind is to install valgrind and KCachegrind:
$ sudo apt-get install valgrind kcachegrind
Compiling Python for use with Valgrind is a bit more involved. There’s a README and a detailed stack overflow post on the subject. Fortunately, your trusty narrator has produced a docker image. Spinning up an instance of Python that you can Valgrind is as easy as:
src/python/valgrind
src/python/$ cat valgrind
#!/bin/sh
docker run -it -v ${PWD}/results:/results rishiramraj/range_n bash
src/python/$ ./valgrind
root@3d0bd3df72f0:/tmp/python2.7-2.7.12# ./python -c 'print("hello world")'
hello world
[21668 refs]
root@3d0bd3df72f0:/tmp/python2.7-2.7.12#
If you’d like to understand the process of compiling Python for use with Valgrind, take a look at env/Dockerfile in the github repo.
Massif
The first Valgrind tool we’ll bring to bear is called Massif. Massif will take periodic snapshots of our program’s heap and stack. It should give us a better idea of how Python is allocating memory over time.
By default, Massif does not track stack memory as stack profiling is slow. We have the luxury of tracing stack as our programs are fairly short running. Another consideration when using Massif is the time unit. Massif can measure time along three different dimensions; instructions executed (i), milliseconds (ms) and bytes allocated (B). The choice of dimension will depend on what you want to highlight. For short programs, bytes allocated often produces the most useful timelines, but feel free to experiment.
Lets start by running the C program with bytes allocated as the time parameter. We should expect a single large peak in the timeline.
src/c/massif
src/c/$ cat massif
#!/bin/sh
valgrind --tool=massif --stacks=yes --time-unit=B ./benchmark
src/c/$ ./massif
==5650== Massif, a heap profiler
==5650== Copyright (C) 2003-2015, and GNU GPL'd, by Nicholas Nethercote
==5650== Using Valgrind-3.11.0 and LibVEX; rerun with -h for copyright info
==5650== Command: ./benchmark
==5650==
==5650==
$ ms_print massif.out.10310
--------------------------------------------------------------------------------
Command: ./benchmark
Massif arguments: --stacks=yes --time-unit=B
ms_print arguments: massif.out.10310
--------------------------------------------------------------------------------
MB
38.15^ #
| #::::::::::::::::::::::::::::::::::
| #
| #
| #
| #
| #
| #
| #
| #
| #
| #
| #
| #
| #
| #
| #
| #
| #
| #
0 +----------------------------------------------------------------------->MB
0 76.51
Number of snapshots: 60
Detailed snapshots: [4, 5, 6, 9, 14, 31, 38, 42, 51 (peak)]
--------------------------------------------------------------------------------
n time(B) total(B) useful-heap(B) extra-heap(B) stacks(B)
--------------------------------------------------------------------------------
0 0 0 0 0 0
1 3,952 624 0 0 624
2 7,304 2,456 0 0 2,456
...
51 40,201,032 40,001,800 40,000,000 1,480 320
100.00% (40,000,000B) (heap allocation functions) malloc/new/new[], --alloc-fns, etc.
->100.00% (40,000,000B) 0x400576: main (benchmark.c:7)
...
The output contains a number of parts: the timeline, a summary of the snapshots, normal snapshots and detailed snapshots. The timeline uses different characters for the various types of snapshots. “:” is used for normal snapshots. “@” is used for detailed snapshots. The peak is illustrated with “#”. The snapshot summary follows the timeline indicating which snapshots are detailed and where the peak occurs.
Normal snapshots present the following information:
- n: The snapshot number.
- time(B): The time it was taken.
- total(B): The total memory consumption at that point.
- useful-heap(B): The number of useful heap bytes allocated.
- extra-heap(B): Bytes in excess of what the program asked for.
- stacks(B): The size of the stack.
Detailed snapshots also provide an allocation tree, which shows locations within the code and their associated percentage of memory usage. As most allocations use either new or malloc, these calls often end up at the top of the tree, accounting for 100% of the memory usage. In our example above, the peak snapshot (snapshot 51) occurs when malloc is called from main, and accounts for 100% of the memory usage.
Now on to the Python program. Unfortunately, the docker volume writes files as root, so the file permissions will have to be changed before you can run ms_print.
src/python/massif
src/python/$ cat massif
#!/bin/sh
docker run -it -v ${PWD}/results:/results rishiramraj/range_n valgrind --tool=massif --stacks=yes --massif-out-file=/results/massif.out --time-unit=B ./python -c 'range(10000000)'
src/python/$ ./massif
==1== Massif, a heap profiler
==1== Copyright (C) 2003-2015, and GNU GPL'd, by Nicholas Nethercote
==1== Using Valgrind-3.11.0 and LibVEX; rerun with -h for copyright info
==1== Command: ./python -c range(10000000)
==1==
[21668 refs]
==1==
src/python/$ cd results
src/python/results/$ sudo chown $USER:$USER massif.out
src/python/results/$ ms_print massif.out
--------------------------------------------------------------------------------
Command: ./python -c range(10000000)
Massif arguments: --stacks=yes --massif-out-file=/results/massif.out --time-unit=B
ms_print arguments: massif.out
--------------------------------------------------------------------------------
MB
482.6^ : @
| @@#::::::@::::::::::::::::@:
| @@@#:: :::@: :::::: :::::::@:
| @@@@@#:: :::@: :::::: :::::::@:
| @@@@ @@@#:: :::@: :::::: :::::::@::
| @@ @@ @@@#:: :::@: :::::: :::::::@:::
| @@@@ @@ @@@#:: :::@: :::::: :::::::@:::
| @@@@@@@ @@ @@@#:: :::@: :::::: :::::::@::::
| @@@@ @@@@ @@ @@@#:: :::@: :::::: :::::::@::::
| @@@@@@ @@@@ @@ @@@#:: :::@: :::::: :::::::@:::::
| @@@@@@@@ @@@@ @@ @@@#:: :::@: :::::: :::::::@::::::
| @@@@@@@@@@ @@@@ @@ @@@#:: :::@: :::::: :::::::@:::::@
| @@@@@@@@@@@ @@@@ @@ @@@#:: :::@: :::::: :::::::@:::::@:
| @@@@@@@@@@@@@@ @@@@ @@ @@@#:: :::@: :::::: :::::::@:::::@:
| :::@@ @@@@@@@@@@@ @@@@ @@ @@@#:: :::@: :::::: :::::::@:::::@::
| @::@@ @@@@@@@@@@@ @@@@ @@ @@@#:: :::@: :::::: :::::::@:::::@::
| :@@@::@@ @@@@@@@@@@@ @@@@ @@ @@@#:: :::@: :::::: :::::::@:::::@:::
| :::@ @::@@ @@@@@@@@@@@ @@@@ @@ @@@#:: :::@: :::::: :::::::@:::::@:::
| :::@ @::@@ @@@@@@@@@@@ @@@@ @@ @@@#:: :::@: :::::: :::::::@:::::@::::
| :::@ @::@@ @@@@@@@@@@@ @@@@ @@ @@@#:: :::@: :::::: :::::::@:::::@::::
0 +----------------------------------------------------------------------->GB
0 5.911
Number of snapshots: 79
Detailed snapshots: [5, 6, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33 (peak), 39, 58, 68, 78]
--------------------------------------------------------------------------------
n time(B) total(B) useful-heap(B) extra-heap(B) stacks(B)
--------------------------------------------------------------------------------
0 0 0 0 0 0
1 86,521,128 1,987,800 1,848,921 121,615 17,264
2 201,080,664 82,752,584 82,565,124 184,628 2,832
3 297,978,512 96,346,400 95,945,124 398,708 2,568
4 417,445,088 113,111,392 112,446,124 662,724 2,544
5 489,564,720 123,233,088 122,408,124 822,116 2,848
...
33 3,184,292,720 501,388,288 494,608,124 6,777,316 2,848
98.65% (494,608,124B) (heap allocation functions) malloc/new/new[], --alloc-fns, etc.
->98.64% (494,591,075B) 0x466C1C: PyObject_Malloc (obmalloc.c:986)
| ->98.64% (494,591,075B) 0x467676: _PyObject_DebugMallocApi (obmalloc.c:1494)
| ->98.28% (492,756,684B) 0x467565: _PyMem_DebugMalloc (obmalloc.c:1444)
| | ->82.18% (412,061,000B) 0x43F3D4: fill_free_list (intobject.c:52)
| | | ->82.18% (412,050,000B) 0x43F4AD: PyInt_FromLong (intobject.c:104)
| | | | ->82.18% (412,043,000B) 0x4CA61D: builtin_range (bltinmodule.c:2008)
| | | | | ->82.18% (412,043,000B) 0x571B0F: PyCFunction_Call (methodobject.c:81)
| | | | | ->82.18% (412,043,000B) 0x4DE975: call_function (ceval.c:4350)
| | | | | ->82.18% (412,043,000B) 0x4D91F5: PyEval_EvalFrameEx (ceval.c:2987)
| | | | | ->82.18% (412,043,000B) 0x4DC0CB: PyEval_EvalCodeEx (ceval.c:3582)
| | | | | ->82.18% (412,043,000B) 0x4CE7AE: PyEval_EvalCode (ceval.c:669)
| | | | | ->82.18% (412,043,000B) 0x50FEF4: run_mod (pythonrun.c:1376)
| | | | | ->82.18% (412,043,000B) 0x50FDAD: PyRun_StringFlags (pythonrun.c:1339)
| | | | | ->82.18% (412,043,000B) 0x50E740: PyRun_SimpleStringFlags (pythonrun.c:974)
| | | | | ->82.18% (412,043,000B) 0x415FE5: Py_Main (main.c:584)
| | | | | ->82.18% (412,043,000B) 0x414CF4: main (python.c:20)
| | | | |
| | | | ->00.00% (7,000B) in 1+ places, all below ms_print's threshold (01.00%)
| | | |
| | | ->00.00% (11,000B) in 1+ places, all below ms_print's threshold (01.00%)
| | |
| | ->15.96% (80,002,024B) 0x4438E6: PyList_New (listobject.c:152)
| | | ->15.96% (80,000,032B) 0x4CA5EF: builtin_range (bltinmodule.c:2004)
| | | | ->15.96% (80,000,032B) 0x571B0F: PyCFunction_Call (methodobject.c:81)
| | | | ->15.96% (80,000,032B) 0x4DE975: call_function (ceval.c:4350)
| | | | ->15.96% (80,000,032B) 0x4D91F5: PyEval_EvalFrameEx (ceval.c:2987)
| | | | ->15.96% (80,000,032B) 0x4DC0CB: PyEval_EvalCodeEx (ceval.c:3582)
| | | | ->15.96% (80,000,032B) 0x4CE7AE: PyEval_EvalCode (ceval.c:669)
| | | | ->15.96% (80,000,032B) 0x50FEF4: run_mod (pythonrun.c:1376)
| | | | ->15.96% (80,000,032B) 0x50FDAD: PyRun_StringFlags (pythonrun.c:1339)
| | | | ->15.96% (80,000,032B) 0x50E740: PyRun_SimpleStringFlags (pythonrun.c:974)
| | | | ->15.96% (80,000,032B) 0x415FE5: Py_Main (main.c:584)
| | | | ->15.96% (80,000,032B) 0x414CF4: main (python.c:20)
| | | |
| | | ->00.00% (1,992B) in 1+ places, all below ms_print's threshold (01.00%)
| | |
| | ->00.14% (693,660B) in 1+ places, all below ms_print's threshold (01.00%)
| |
| ->00.37% (1,834,391B) in 1+ places, all below ms_print's threshold (01.00%)
|
->00.00% (17,049B) in 1+ places, all below ms_print's threshold (01.00%)
...
Two interesting observations can be drawn from this output that corroborate our findings with ltrace and strace. The first thing we observe is from the timeline; Python is allocating an order of magnitude more memory when compared to the C program (around 480 MB). This memory grows over time instead of being allocated all at once.
The second thing we observe is from the detailed snapshot of the peak; something other than the large list allocation made by PyList_New is consuming the bulk of the allocated memory. This function is called fill_free_list and likely accounts for the 243929 allocations we saw earlier.
This snapshot gives us a partial look into the internals the C Python interpreter. It’s interesting to note that PyList_New and fill_free_list have a common ancestor in builtin_range. If we were brave enough, we could dive into the source code at this point. Fortunately there’s better tooling we can use to save us a bit of time.
DHAT
Before we dive into the code using callgrind, let’s see if we can figure out how the additional memory we identified with Massif is being used. For that job we will use DHAT, which provides summarized statistics on heap allocations. Back to our C program:
src/c/dhat
src/c/$ cat dhat
#!/bin/sh
valgrind --tool=exp-dhat ./benchmark
src/c/$ ./dhat
==17163== DHAT, a dynamic heap analysis tool
==17163== NOTE: This is an Experimental-Class Valgrind Tool
==17163== Copyright (C) 2010-2015, and GNU GPL'd, by Mozilla Inc
==17163== Using Valgrind-3.11.0 and LibVEX; rerun with -h for copyright info
==17163== Command: ./benchmark
==17163==
==17163==
==17163== ======== SUMMARY STATISTICS ========
==17163==
==17163== guest_insns: 100,110,715
==17163==
==17163== max_live: 40,000,000 in 1 blocks
==17163==
==17163== tot_alloc: 40,000,000 in 1 blocks
==17163==
==17163== insns per allocated byte: 2
==17163==
==17163==
==17163== ======== ORDERED BY decreasing "max-bytes-live": top 10 allocators ========
==17163==
==17163== -------------------- 1 of 10 --------------------
==17163== max-live: 40,000,000 in 1 blocks
==17163== tot-alloc: 40,000,000 in 1 blocks (avg size 40000000.00)
==17163== deaths: 1, at avg age 100,001,087 (99.89% of prog lifetime)
==17163== acc-ratios: 0.00 rd, 1.00 wr (0 b-read, 40,000,000 b-written)
==17163== at 0x4C2BE7F: malloc (in /usr/lib/valgrind/vgpreload_exp-dhat-amd64-linux.so)
==17163== by 0x400577: main (benchmark.c:7)
...
DHAT provides a number of summary statistics followed by a sorted list of memory allocators. Here are a number of definitions for terms used by the tool:
- block: A memory allocation; i.e. a call to malloc.
- guest_insns: Total number of instructions.
- max_live: The maximum number of blocks simultaneously allocated.
- tot_alloc: Memory allocation over the history of the program.
- deaths: Memory deallocation over the history of the program.
- acc-ratios: Read and write access ratios.
Understanding how to interpret the results from DHAT is the key to its usefulness. For example, an average death that is comparable to the length of the program implies that memory is all being deallocated at the end.
Read or write ratios of less than 1 imply that memory is either not being read from or written to. DHAT will also provide access counts per offset into a buffer, to make alignment problems easier to diagnose. An alignment problem will show up as a portion of the block that is not accessed and therefore filled with 0 counts. We’ll see a offset matrix in the Python example.
In our C example, we observe 100 million instructions which are likely used to seed the block. We also see a 40MB memory allocation as expected. By looking at the deaths measurement, the allocation lives for the duration of the programs execution. The allocation ratios tell us that the allocation is only written to once and never read. Now for the Python example:
src/python/dhat
src/python/$ cat dhat
#!/bin/sh
docker run -it rishiramraj/range_n valgrind --tool=exp-dhat ./python -c 'range(10000000)'
src/python/$ ./dhat
==1== DHAT, a dynamic heap analysis tool
==1== NOTE: This is an Experimental-Class Valgrind Tool
==1== Copyright (C) 2010-2015, and GNU GPL'd, by Mozilla Inc
==1== Using Valgrind-3.11.0 and LibVEX; rerun with -h for copyright info
==1== Command: ./python -c range(10000000)
==1==
[21668 refs]
==1==
==1== ======== SUMMARY STATISTICS ========
==1==
==1== guest_insns: 2,753,608,005
==1==
==1== max_live: 499,221,126 in 429,745 blocks
==1==
==1== tot_alloc: 501,946,111 in 439,591 blocks
==1==
==1== insns per allocated byte: 5
==1==
==1==
==1== ======== ORDERED BY decreasing "max-bytes-live": top 10 allocators ========
==1==
==1== -------------------- 1 of 10 --------------------
==1== max-live: 416,656,000 in 416,656 blocks
==1== tot-alloc: 416,656,000 in 416,656 blocks (avg size 1000.00)
==1== deaths: 416,656, at avg age 1,814,285,338 (65.88% of prog lifetime)
==1== acc-ratios: 2.91 rd, 4.46 wr (1,216,634,728 b-read, 1,860,368,408 b-written)
==1== at 0x4C2BE7F: malloc (in /usr/lib/valgrind/vgpreload_exp-dhat-amd64-linux.so)
==1== by 0x466C1D: PyObject_Malloc (obmalloc.c:986)
==1== by 0x467677: _PyObject_DebugMallocApi (obmalloc.c:1494)
==1== by 0x467566: _PyMem_DebugMalloc (obmalloc.c:1444)
==1== by 0x43F3D5: fill_free_list (intobject.c:52)
==1== by 0x43F4AE: PyInt_FromLong (intobject.c:104)
==1== by 0x4CA61E: builtin_range (bltinmodule.c:2008)
==1== by 0x571B10: PyCFunction_Call (methodobject.c:81)
==1== by 0x4DE976: call_function (ceval.c:4350)
==1== by 0x4D91F6: PyEval_EvalFrameEx (ceval.c:2987)
==1== by 0x4DC0CC: PyEval_EvalCodeEx (ceval.c:3582)
==1== by 0x4CE7AF: PyEval_EvalCode (ceval.c:669)
==1==
==1== Aggregated access counts by offset:
==1==
==1== [ 0] 1666624 1666624 1666624 1666624 1666624 1666624 1666624 1666624 1249968 1249968 1249968 1249968 1666624 1249968 1249968 1249968
==1== [ 16] 1874953 1874953 1874953 1874953 1874953 1874953 1874953 1874953 3124916 3124916 3124916 3124916 3124916 3124916 3124916 3124916
==1== [ 32] 4791534 4791534 4791534 4791534 4791534 4791534 4791534 4791534 3124914 3124914 3124914 3124914 3124914 3124914 3124914 3124914
==1== [ 48] 3749899 3749899 3749899 3749899 3749899 3749899 3749899 3749899 1249967 1249967 1249967 1249967 1249967 1249967 1249967 1249967
==1== [ 64] 2916587 2916587 2916587 2916587 2916587 2916587 2916587 2916587 4583207 4583207 4583207 4583207 4583207 4583207 4583207 4583207
==1== [ 80] 2916587 2916587 2916587 2916587 2916587 2916587 2916587 2916587 3749899 3749899 3749899 3749899 3749899 3749899 3749899 3749899
==1== [ 96] 1249967 1249967 1249967 1249967 1249967 1249967 1249967 1249967 2916587 2916587 2916587 2916587 2916587 2916587 2916587 2916587
...
==1== [ 960] 2916592 2916592 2916592 2916592 2916592 2916592 2916592 2916592 3749904 3749904 3749904 3749904 3749904 3749904 3749904 3749904
==1== [ 976] 1249968 1249968 1249968 1249968 1249968 1249968 1249968 1249968 1666624 1666624 1666624 1666624 1666624 1666624 1666624 1666624
==1== [ 992] 833312 833312 833312 833312 833312 833312 833312 833312
==1==
==1== -------------------- 2 of 10 --------------------
==1== max-live: 80,000,032 in 1 blocks
==1== tot-alloc: 80,000,032 in 1 blocks (avg size 80000032.00)
==1== deaths: 1, at avg age 2,352,467,568 (85.43% of prog lifetime)
==1== acc-ratios: 2.99 rd, 3.99 wr (240,000,032 b-read, 320,000,089 b-written)
==1== at 0x4C2BE7F: malloc (in /usr/lib/valgrind/vgpreload_exp-dhat-amd64-linux.so)
==1== by 0x466C1D: PyObject_Malloc (obmalloc.c:986)
==1== by 0x467677: _PyObject_DebugMallocApi (obmalloc.c:1494)
==1== by 0x467566: _PyMem_DebugMalloc (obmalloc.c:1444)
==1== by 0x4438E7: PyList_New (listobject.c:152)
==1== by 0x4CA5F0: builtin_range (bltinmodule.c:2004)
==1== by 0x571B10: PyCFunction_Call (methodobject.c:81)
==1== by 0x4DE976: call_function (ceval.c:4350)
==1== by 0x4D91F6: PyEval_EvalFrameEx (ceval.c:2987)
==1== by 0x4DC0CC: PyEval_EvalCodeEx (ceval.c:3582)
==1== by 0x4CE7AF: PyEval_EvalCode (ceval.c:669)
==1== by 0x50FEF5: run_mod (pythonrun.c:1376)
...
We have about 480 MB of memory allocated in total. The top two allocations are those predicted by Massif; fill_free_list and PyList_New respectfully. The memory allocated by fill_free_list only survives for 65% of the program’s lifetime, whereas the memory allocated by PyList_New survives for 85% of the program’s lifetime.
We can infer that our large 80MB buffer is allocated before the smaller 1KB buffers and deallocated after the 1KB buffers are deallocated. Interestingly, both the 80MB buffer and 1KB buffers are read and written to with similar access ratios; read around 3 times and written to around 4 times.
Aggregated access counts are also presented for the fill_free_list allocation. DHAT will produce this report for buffers that are 4096 bytes or smaller. The report counts the number of accesses that are offset from the start of the block in byte increments. It is read from left to right, top to bottom.
The top left of the report shows you the access count for the first byte (i.e. the start of the block). Row 0, column 1 shows you the count 1 byte after the start. Row 1, column 0 shows you the count for the byte 16 bytes after the start. As we are seeing no 0 counts, it seems that the block is well packed; memory cannot be moved around to reduce the size of the buffer. We can also infer that different portions of the buffer are used for different purposes, as the counts are not uniform.
Callgrind
Going back to our hypothesis, we proposed that allocating a large list in Python was increasing our total runtime. We’ve found that a large number of instructions were being used to allocate additional memory, and they seem to be related to the construction of our list. Now its time to start taking a look at code.
Instead of guessing where the problem might live in the source code, it would be useful to have a visualization of how the interpreter operates and how frequently parts of the code is called. That is precisely what Callgrind and KCachegrind can do for us. On to the C program:
src/c/callgrind
src/c/$ cat callgrind
#!/bin/sh
valgrind --tool=callgrind ./benchmark
src/c/$ ./callgrind
==5966== Callgrind, a call-graph generating cache profiler
==5966== Copyright (C) 2002-2015, and GNU GPL'd, by Josef Weidendorfer et al.
==5966== Using Valgrind-3.11.0 and LibVEX; rerun with -h for copyright info
==5966== Command: ./benchmark
==5966==
==5966== For interactive control, run 'callgrind_control -h'.
==5966==
==5966== Events : Ir
==5966== Collected : 100153094
==5966==
==5966== I refs: 100,153,094
src/c/$ kcachegrind
If all goes well, you should have a window that looks like this:
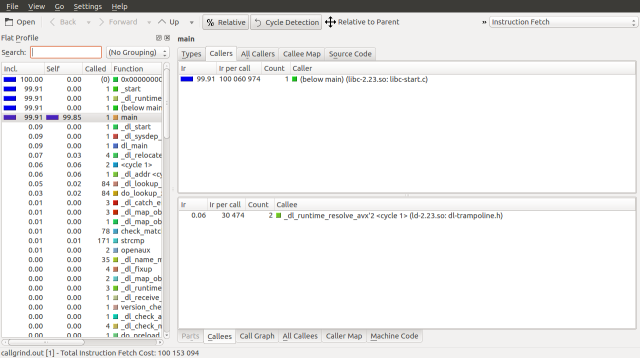
First two basic concepts, starting with an event. Callgrind and Cachegrind (the tool that Callgrind is based on) monitor events that occur within a program. The default event that Callgrind will monitor is called an instruction fetch. When a program is run, its instructions are first loaded into memory. In order to get the next set of instructions that the processor needs it performs an instruction fetch from memory; these events therefore correspond to the lines of code that compose the program.
Callgrind and Cachegrind are capable of monitoring more than just instruction fetches. They can also monitor events like memory cache misses. In our investigation we will be using instruction fetches. You can change the event type used to profile the system using the drop down in the upper right corner or the types tab. Changing the event type will change how the various instructions are costed. See the Cachegrind documentation for more information on events.
The second basic concept is a cycle. A cycle is a group of functions which call each other recursively. Cycles make profiling harder because the code is no longer ordered hierarchically, but the execution of that code is. Certain execution paths may cost more, but accounting for that cost is convolved with other parts of the cycle.
KCachegrind attempts to remove this complexity with a feature called cycle detection. Cycle detection collapses cycles into single blocks and profiles the main branches of the cycle. This feature allows you continue to use the call graph, guided by cost, to find bottlenecks. As we are interested in seeing the structure of the code, we will turn cycle detection off. To toggle cycle detection, press the cycle detection button.
There are a few components of the UI that we can quickly review as well. Back and forward act like a web browser’s history. Up traverses up the call graph. If you go to Settings->Side Bars->Call Stack, you’ll get a “most probable” call stack. Settings->Side Bars->Parts Overview will list different output files if your callgrind command produces multiple outputs. In our case, we will only be examining one output, so this side bar is unnecessary.
By default, KCachegrind will display a Flat Profile on the side bar. This profile displays a global list of functions and their cost. This list can be grouped in a number of ways by going to View->Grouping. In this example we will be using the Flat Profile.
The remaining UI components are found as tabs in the main area of the application. Types is a list of event types available for profiling. The Call Graph is a visualization of the call graph.
Callers are a list of functions that invoke the current function. All Callers are a list looking all the way up the call graph. In a similar manner, Callees and All Callees look down the call graph. The Callee Map looks down the call graph and arranges the proportions of the graph visually. Conversely the Caller Map looks up.
If debugging symbols are enabled, Source Code displays the source for the target function. If the –dump-instr flag is used, then Machine Code will be displayed. We’re not debugging machine code in this investigation.
To set up the UI for our investigation, we will want to cost using Instruction Fetch turn off Cycle Detection, view the Source Code and Call Graph tabs, and turn on the Call Stack. Your interface should look like this:
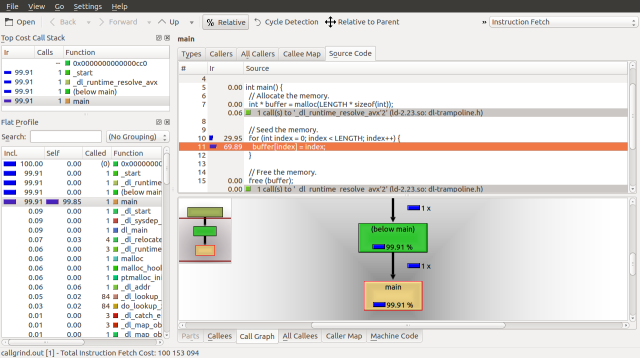
If you misconfigure KCachegrind, you can reset settings by removing the following file:
$ rm ~/.kde/share/config/kcachegrindrc
By taking a look at the source code for our C program above, we can see that the vast majority of time is spent seeding memory. 29.95% of the runtime is spent in the for loop and the remaining 69.89% is spent setting the buffer to the index value.
Before we can get the Python program running with KCacheGrind, we will need to check out the Python source code. The docker container checks out the source code in /tmp and compiles Python with debugging symbols on. In order for our local install of KCacheGrind to be able to access the source, we will need to do the same on our system. Note that you will need to enable your source code repositories in apt for this to work (see System Settings->Software & Updates).
$ cd /tmp
/tmp/$ apt-get source python2.7
Now, on to Python. As in the Massif example, we will have to change ownership of the output file.
src/c/callgrind
src/python/$ cat callgrind
#!/bin/sh
docker run -it -v ${PWD}/results:/results rishiramraj/range_n valgrind --tool=callgrind --callgrind-out-file=/results/callgrind.out ./python -c 'range(10000000)'
src/python/$ ./callgrind
==1== Callgrind, a call-graph generating cache profiler
==1== Copyright (C) 2002-2015, and GNU GPL'd, by Josef Weidendorfer et al.
==1== Using Valgrind-3.11.0 and LibVEX; rerun with -h for copyright info
==1== Command: ./python -c range(10000000)
==1==
==1== For interactive control, run 'callgrind_control -h'.
==1== brk segment overflow in thread #1: can't grow to 0x4a2b000
...
==1== brk segment overflow in thread #1: can't grow to 0x4a2b000
[21668 refs]
==1==
==1== Events : Ir
==1== Collected : 2899174708
==1==
==1== I refs: 2,899,174,708
src/python/$ cd results
src/python/results/$ sudo chown $USER:$USER callgrind.out
src/python/results/$ kcachegrind
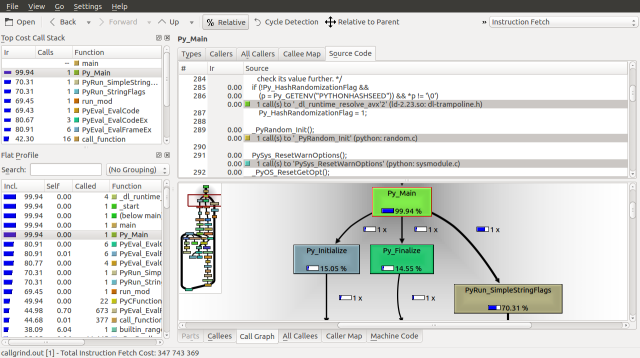
Traversing down the Call Graph, we can see our first fork at Py_Main. 83.4% of the runtime is spent on PyRun_SimpleStringFlags and 14.79% is spent on Py_Finalize. Following the PyRun_SimpleStringFlags branch down we find it splits again at PyEval_EvalFrameEx. A frame is a function call along with its arguments, on the call stack.
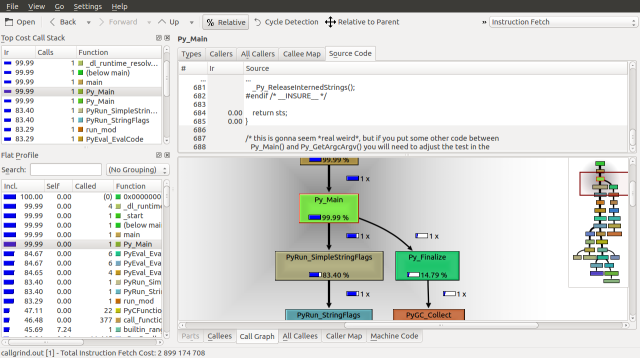
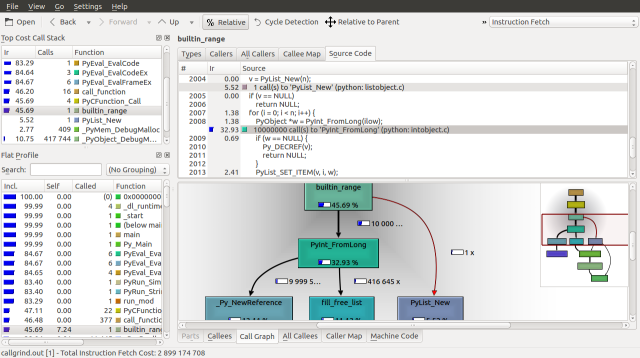
Looking down the Call Graph further, we find that 36.56% of the runtime is spent deallocating our list with the list_dealloc call and 43.32% of the runtime is spent calling the builtin_range function, which creates our list. These functions call _Py_Dealloc and PyInt_FromLong respectfully, which seem to be order n operations, as they are called about 10,000,000 times.
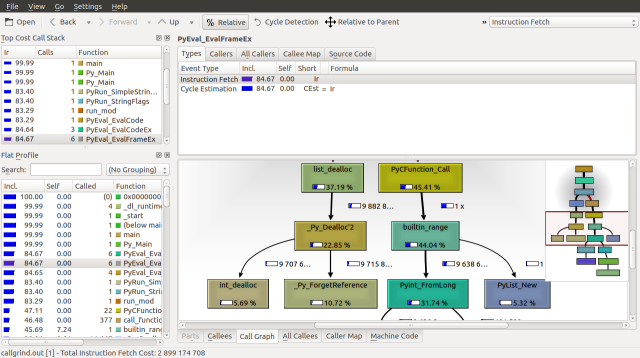
If we inspect the source for builtin_range we can see the PyInt_FromLong and fill_free_list calls, along with how frequently they are called. We can make three observations. The first is that python seems to be maintaining a linked list of objects called free_list. The second is that fill_free_list, which allocates memory according to our Massif analysis is only called only 416,663 times. The third is that the order n operation associated with PyInt_FromLong is the initialization of 9,999,970 PyIntObjects.
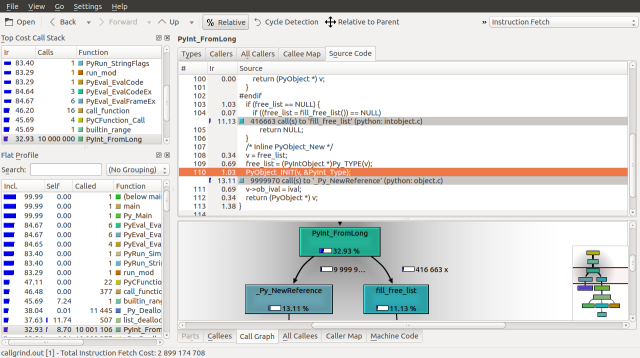
Lets dig deeper into this source file to see if we can find the definition for a PyIntObject and the meaning of free_list. I personally use ctags to explore source code, but feel free to use whatever method you feel comfortable with. The definition of a PyIntObject is found in Include/intobject.h, lines 23 to 26:
typedef struct {
PyObject_HEAD
long ob_ival;
} PyIntObject;
The definition of the PyObject_HEAD statement is found in Include/object.h on lines 78 to 81:
/* PyObject_HEAD defines the initial segment of every PyObject. */
#define PyObject_HEAD \
_PyObject_HEAD_EXTRA \
Py_ssize_t ob_refcnt; \
struct _typeobject *ob_type;
It seems that a PyIntObject is an integer that has been wrapped with a reference count and a type. If we look at the source for _Py_NewReference, in Objects/objects.c lines 2223 to 2230, we can see how it is initialized. On the surface, it also seems that the object is added to a global list of objects, but some quick digging (Objects/object.c, lines 40 to 43) suggests that this feature is only enabled when Py_TRACE_REFS is defined. We can likely disregard the 7.61% that is spent on _Py_AddToAllObjects.
void
_Py_NewReference(PyObject *op)
{
_Py_INC_REFTOTAL;
op->ob_refcnt = 1;
_Py_AddToAllObjects(op, 1);
_Py_INC_TPALLOCS(op);
}
When looking up free_list we find the following comments at the top of Objects/intobject.c on lines 25-30:
/*
block_list is a singly-linked list of all PyIntBlocks ever allocated,
linked via their next members. PyIntBlocks are never returned to the
system before shutdown (PyInt_Fini).
free_list is a singly-linked list of available PyIntObjects, linked
via abuse of their ob_type members.
*/
Digging deeper into fill_free_list (Objects/intobject.c, lines 47 to 65), we find that integer objects are allocated in blocks and individually linked rear to front using their ob_type:
static PyIntObject *
fill_free_list(void)
{
PyIntObject *p, *q;
/* Python's object allocator isn't appropriate for large blocks. */
p = (PyIntObject *) PyMem_MALLOC(sizeof(PyIntBlock));
if (p == NULL)
return (PyIntObject *) PyErr_NoMemory();
((PyIntBlock *)p)->next = block_list;
block_list = (PyIntBlock *)p;
/* Link the int objects together, from rear to front, then return
the address of the last int object in the block. */
p = &((PyIntBlock *)p)->objects[0];
q = p + N_INTOBJECTS;
while (--q > p)
Py_TYPE(q) = (struct _typeobject *)(q-1);
Py_TYPE(q) = NULL;
return p + N_INTOBJECTS - 1;
}
The address of the last object in the block is returned and is tracked by the free_list pointer in PyInt_FromLong (Objects/intobject.c, lines 103 to 112).
if (free_list == NULL) {
if ((free_list = fill_free_list()) == NULL)
return NULL;
}
/* Inline PyObject_New */
v = free_list;
free_list = (PyIntObject *)Py_TYPE(v);
PyObject_INIT(v, &PyInt_Type);
v->ob_ival = ival;
return (PyObject *) v;
When a new allocation is made, free_list moves forward in the block via its ob_type. The ob_type of the integer object at the beginning of the block is NULL. If free_list is NULL when the next integer is created, a new block is allocated. This process is illustrated below:
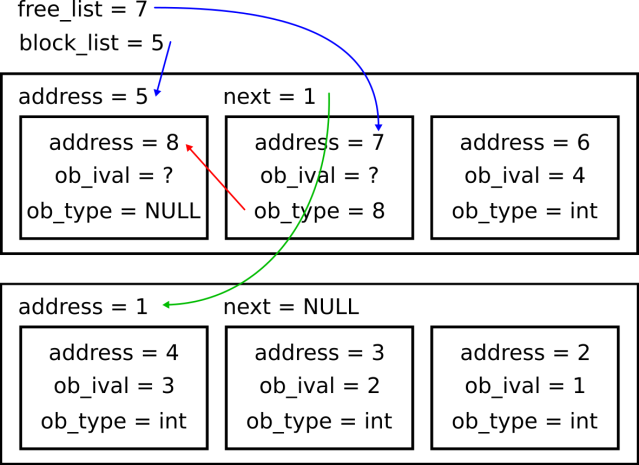
A quick glance at list_dealloc seems to suggest that the bulk of its runtime is spent decreasing reference counts:
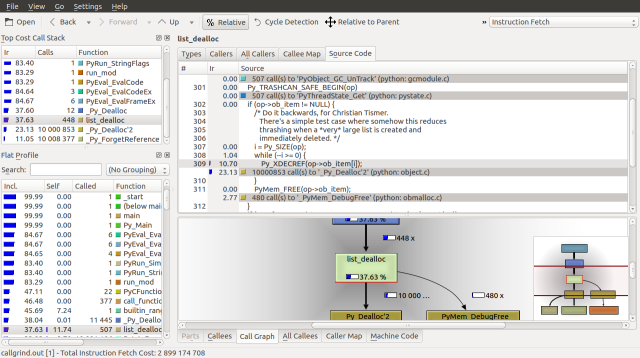
Similarly, a glance at the PyInt_ClearFreeList function, which accounts for the bulk of the Py_Finalize time suggests that the 14.39% of the runtime is spent traversing block_list and free_list to deallocate the memory allocated by fill_free_list.
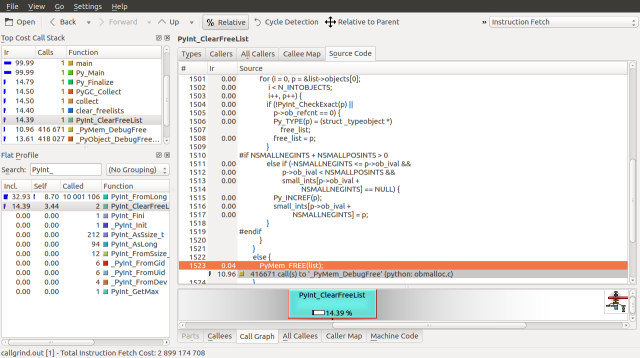
If we use the detailed snapshot from our Massif example, we can also pinpoint the large list allocation created by PyList_New, which is called from builtin_range. This allocation costs only 5.52% of our runtime. Looking at the source, we can infer that the large memory block contains references to the PyIntObjects created above. These references seem to be set by PyList_SET_ITEM.
KCachegrind will trim the call graph to expose only those functions that have significant cost. If you’re interested in exploring the execution of the interpreter further, you can get interesting insights by reducing the size of the range call to 1,000,000:
src/python/$ docker run -it -v ${PWD}/results:/results rishiramraj/range_n valgrind --tool=callgrind --callgrind-out-file=/results/callgrind.out ./python -c 'range(1000000)'
==1== Callgrind, a call-graph generating cache profiler
==1== Copyright (C) 2002-2015, and GNU GPL'd, by Josef Weidendorfer et al.
==1== Using Valgrind-3.11.0 and LibVEX; rerun with -h for copyright info
==1== Command: ./python -c range(1000000)
==1==
==1== For interactive control, run 'callgrind_control -h'.
==1== brk segment overflow in thread #1: can't grow to 0x4a2b000
...
==1== brk segment overflow in thread #1: can't grow to 0x4a2b000
[21668 refs]
==1==
==1== Events : Ir
==1== Collected : 347743369
==1==
==1== I refs: 347,743,369
src/python/$ cd results
src/python/results/$ sudo chown $USER:$USER callgrind.out
src/python/results/$ kcachegrind
Among other things, this profile includes the initialization and module loading code. Unfortunately, that’s an article for another day.
Conclusions
Wow that was a long article, but mystery solved.

Breaking down the runtime of our Python program, we now build an overall picture of how Python allocates and deallocates a large list of integers. Note that this decomposition is based on instruction fetches, and not the actual time spent on each instruction.
- 83.4%: PyRun_SimpleStringFlags
- 43.32%: builtin_range
- 5.5%: PyList_New: Allocate a large buffer for the list.
- 32.92%: PyInt_FromLong
- 11.13%: fill_free_list: Allocate blocks of memory for integer objects.
- 13.11%: _Py_NewReference: Set reference counts for integer objects.
- 36.56%: list_dealloc: Decrease reference counts.
- 14.79%: Py_Finalize: Deallocate integer memory blocks.
The size of n in both cases is 10,000,000 integers. According to Callgrind, the C program used 100,153,094 instruction reads to implement that allocation. The Python program used 2,899,174,708 instruction reads. That’s a ratio of 10:1 instructions per integer in C and 290:1 instructions in Python, in this specific example. In exchange for the additional cycles, Python gives us lists that can be used to contain a range of types and memory management for our integers.
There’s also one very important observation to note from Objects/intobject.c, lines 26, 27:
/*
PyIntBlocks are never returned to the system before shutdown (PyInt_Fini).
*/
This particular observation is noteworthy for long running processes. If you find your process running short on memory, it’s worth checking to see if it allocates a large number of integers.
So what can you do if you need a large list of integers? The easiest solution is to allocate them with a primitive that doesn’t use Python’s memory manager. Available primitives include those from the array module, those from numpy and the multiprocessing.Array primitive for shared memory. You will have to take care to ensure that the process of seeding the memory does not create additional overhead.
With any luck, I’ve been able to successfully introduce you to a set of neat tools and have provided a deeper understanding of how Python manages memory. Practice these skills well, ride the length and breath of the land, and autonomous collectives everywhere will regard your coming favorably.









































{kind=link}